4 Variation and differences
In the Section 3 we examined how individuals varied within a population and how common statistical quantities describe that variation. In this section we will examine how variation within a population affects our ability to detect differences.
4.1 Getting "the answer"
In the first Lab, you did a series of dilutions and plated the bacteria. This week, you will be counting the colonies. Your TA may have a brief discussion on the collection of the data for the entire Bay as part of the data set. Inevitably, once you count your plate and look at your partner's plate and even the other people colony data, this thought/question occurs: "My plate numbers are different, therefore I did something wrong. I am going to embarrassed to say this out loud since I am the only person who is unsure/feels clueless in this Lab right now." Most assuredly, most if not all of the students in each section has that feeling. So let's talk about it.
Here is the general logic used by most students:
1. There is a right answer, a proper number of colonies to get for this part of the homework. The teacher knows it and my job is to find out what it is.
2. Because the homework asks about getting a titer based on the data, there has to be a better value or way to do this because otherwise, why would we be doing the lab?
3. My answer is different than my partner's plate and my plate is also different than the other person in the Bay who had the same dilution factor for the bacteria like me, therefore I am wrong.
4. Therefore I have messed up and must be making a big mistake somewhere. I need to find out what I did wrong, otherwise I will get a bad grade and will never make it into medical school.
Time to take a deep breath. In no way should anyone be starting to get anxious or nervous or anything at this point. First (#4), literally one grade in your introductory biology lab will not impact Med School, or any other post graduate program. Let's all just stop there on that.
Second, (#2), the ways we present things in the course are generally the best ways. If there was a better way, we would do it already.
Third, (#1 and #4) is showing the real issue. The need to pay attention to the Reading and that first and foremost you are not being assessed on the actual result you get, but the analysis of the data. And that is because of this question: Did YOU know how many colonies to expect to get on the plate before you did anything? No. If so, you would be the first student ever to be able to do so!
Before we talk about this further, let's talk about the number of children a family has. If the parents have four children, what would the children be? How many girls and boys? Most of you have given "the answer" that there should be 2 and 2. Now, you might be in a different family or know of one like this that has 3 or 4 or more children; how many of you know of families like this with at least three children and all three are girls or all three are boys?
What did those parents do wrong? With even three children, should not at least one of them have been the opposite sex? We have a 50:50 gender ratio for birth. So what did every family with multiple children do wrong and they have only girls or only boys?
Your reply should be something like, "The 50:50 ratio is not a hard rule, but a general one. Every birth is going to be a 50:50 for one or the other, and by chance some families end having all girls or all boys."
Correct.
How does it happen that nearly all of the smart, capable, and motivated Vanderbilt undergrads in this class come to the incorrect conclusion (that they are automatically wrong) in this circumstance? A possible explanation is this: you have never been given a real opportunity to think. In elementary school, children may be encouraged to observe and draw conclusions in a low-stakes environment, that you are free to express an idea whether valid or not. But as high school approaches, the pressure builds to get good grades and high test scores. In response, students become experts at figuring out what their teachers want and how to produce answers that are "right". They have few experiences dealing with situations where the answer is not known, or where it is impossible to be certain that an answer is correct. The situation is exacerbated by experiences in chemistry and physics classes, where matter is very well behaved and advanced measuring technology allows some physical characteristics to be measured accurately to 4 or more significant digits. And to add to that pressure, you've got the internet that "has all the answers to everything" in your hand on your phone! They come to expect that they can, and should, be able to produce "the answer" with a high degree of precision.
These experiences put students on a collision course with real-world biology. In real-world biology, there are a lot of things we do not know. Because living organisms and systems are a lot more variable and a lot less well behaved than the simpler materials studied in chemistry and physics, there is uncertainty in most everything we work with. Thus, one of our major goals in this course is to help students get over their discomfort with uncertainty, and to give them the tools to quantify variability and make decisions in uncertain situations. One of the first steps in this direction is to understand why results vary.
Going back to the bacteria numbers, you and your partner (if you followed the instructions <Reading> each did a dilution and each plated a different suspension of bacteria. Of course your two plates will be different in numbers. In comparing your plate to another person with the same dilution factor, what is the chance that both of you pipetted exactly the same at every step and spread both plates identically? There should be some discussion on this during lab with your TA and also....relax a little will ya'!!! You are not going to cure cancer this week in Lab and you have a lot to learn. It takes time, practice, and remember, how many colonies you got is not what matters. What matters is what you learn from it and the analysis of the data.
4.2 Sources of variability
Imagine that you are a biomedical researcher and you are investigating a new form of a high blood pressure drug that is being developed by your company. According to the published literature, the previous form of the drug lowered blood pressure by 12 mm Hg. You administer your new version of the drug to a patient and find that it lowered the patient's blood pressure by 16 mm Hg. You begin to imagine yourself in Stockholm accepting your Nobel Prize in medicine.
Not so fast! How do you know that your new version really lowers a patient's blood pressure 4 mm Hg below the current drug? There are three possible reasons why your patient's blood pressure decrease is different from the decrease caused by the current drug (actually there is a fourth reason - the value published in the literature could be wrong, but for our purposes we will assume that value is correct):
4.2.1 Experimental error. There could be something about the way that the experiment is being conducted that is causing you to mismeasure the true effect of the drug. For example, the blood pressure cuff you are using to measure the patient may be out of calibration and is systematically skewing the measurements by a certain amount. A machine used to manufacture the drug may have a loose bolt and be randomly adding larger or smaller amounts of the drug to the filler used to deliver the drug. Your technician may be careless and not bother to measure the dose carefully. This source of variation is the one most likely to be blamed by students for unexpected results, but if careful attention is paid to quality control and standardizing the experimental protocol, it is actually probably the smallest contributor to variation in results.
4.2.2 Intrinsic variation. Patients are humans and humans are by their nature variable. There are many uncontrollable aspects of a subject's life that could affect his or her response to a drug, including what they had for breakfast, whether they were suffering from an illness, and their general health at that time in their life. If the very same dose of drug were given to the very same patient on another day, it is unlikely that the exact same decline in blood pressure would occur. You would have a better idea of the drug's affect if you repeated the test on the same subject on several different days, but even so you would only be measuring the effect on that particular person. In a drug test, we are more interested in the effect of the drug on people in general. Because of differences in genetics and the particular environment in which people live, we expect that the different people will have different responses to a drug, so we need to test many different subjects before we can generalize our conclusions.
4.2.3 Experimental effect. This is the source of variation in which we are actually interested. It is the amount that the blood pressure decline is changed by the effect of the new version of the drug. If the effect of the new drug is small, it will be hard to notice in comparison to the variability among patients receiving the drug. So we would like to make the experimental effect as large as possible. One possible strategy would be to increase the effect by increasing the dose of the drug. However, that could also have the undesired effect of killing the patient!
In any given situation, the actual variation in a particular result may be a combination of all three of the sources of variation described above. For example, of the 4 mm Hg difference between the response of your patient to the new drug and the response of patients in general to the old drug, 1 mm Hg might be due to technician error in reading the blood pressure, 2 mm Hg might be because your particular patient responds to blood pressure drugs more sensitively than the general public, and 1 mg Hg might be due to the new drug's increased effectiveness over the old drug. In that scenario, the effect of the drug would probably be so small that its development is a waste of time. On the other hand, your technician might be really good and read the scale exactly, your patient might be having a response 9 mm Hg less than the general public because he is actually less sensitive to blood pressure medication than average, meaning that for an average person the new drug would actually lower blood pressure by 13 mm Hg more than the old drug. In that case, the new drug would be a great improvement over the old one. Another possibility is that there is actually no difference between the new drug and the old drug and that all of the variability is due to experimental error and intrinsic variation.
4.3 Describing causes of variability
To understand the possibilities better, we need to consider this one particular result in the context of all possible results. In many situations, if we measure a large number of individuals and plot the frequency of each measured value (i.e. the number of times that we got that value) versus the magnitude of the value, a curve similar to the one shown below usually results. This shape of curve is called the standard curve (also known as the "bell-shaped curve").

Fig. 5 Variation in population response to an experimental treatment
The peak of the standard curve is located at the mean (average) value for the population. In the specific case of the drug test example, the peak of the curve could represent the average decrease in blood pressure as a response to the old drug for people in general. Individuals in the population differ in many kinds of little ways, and each of these ways can cause their response to be shifted slightly higher or lower. In many cases, small differences that shift the response higher are greater than the small differences that shift the response lower. So there are quite a few people who have responses a little greater than average. In relatively few cases, by chance individuals experience a lot of small differences that shift their response higher and experience only a few differences that shift their response lower. So there are only a few people with responses a lot higher than average. The same corresponding situation holds for situations where there are more small differences that shift the response lower than higher. Thus the curve is symmetric with "tails" that get smaller at values further from the mean.

Fig. 6 Variation in population response under more carefully controlled conditions
Although it is impossible to eliminate all variability in a population, we can reduce it if we carefully control the conditions of our experiment. For example, if we limit the subjects of the experiment to women between the ages of 20 and 30, have them eat a standardized diet during the 24 hours before the experiment, and measure all their blood pressure changes at the same time of day, we may be able to eliminate a lot of the small differences among subjects that contribute to the variability and narrow the standard curve as shown in Fig.6. Using the terminology from last week, we can say that we have reduced the standard deviation of the population.
4.4 Alternative explanations of results
Let's return to the example of our blood pressure drug trial. For the time being, let's assume that the new version of the blood pressure drug actually lowers blood pressure a lot more than the old drug. This scenario is illustrated in Fig. 7. The curve at the left represents the response of the test subjects to the old drug. The average response of subjects to the old drug was 12 mm Hg, but you can see that many participants had responses as low as 8 and as high as 16. The response of the same group of test subjects to the new drug is illustrated by the curve on the right. The average response to the new drug is a lot higher (about 25 mm Hg). The vertical line represents the bresponse of our one test subject whose blood pressure was lowered by 16 mm Hg. You can see that under this scenario, by chance we were unlucky and picked a test subject who was less responsive to the new drug than normal.

Fig. 7 Illustration of hypothesis that the new drug lowers blood pressure more than the old drug (the "alternative hypothesis")
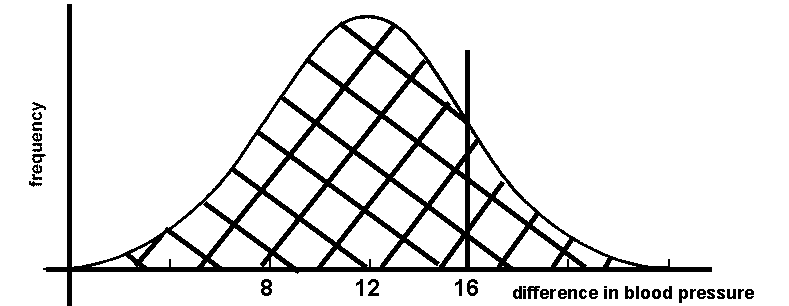
Fig. 8 Illustration of hypothesis that the new drug lowers blood pressure just as much as the old drug (the "null hypothesis")
Fig. 8 shows another possible scenario. In this scenario, the new version of the blood pressure drug is a failure because it doesn't work any better than the old version. Test subjects respond exactly the same to the new drug as they do to the old drug and the normal curves representing the two drug responses are exactly on top of each other. Under this scenario, our one test subject whose blood pressure was lowered by 16 mm Hg was actually more responsive to the drug than average.
So which of these two hypotheses is correct? With a single test subject there is absolutely no way that we can have any idea whether one hypothesis is supported more than the other. In order to know whether the response curve of subjects to the new drug is different than the response curve to the old curve, we will need to test enough people to determine the actual shape of the curve.
Let's return to our original discussion of the causes of variability to see how they are related to the figures above. If the experimental error has a random effect (such as sloppiness in measuring or the loose bolt), then it contributes to a larger standard deviation (i.e. Fig. 5 vs. Fig. 6) of the response curves. Random experimental error can be reduced by carefully controlling the conditions under which the experiment is conducted. The result would be a decrease in the area of overlap in Fig. 7, which would make it easier to tell whether the two curves were different. If an experimental error was systematic (as in the example of the badly calibrated pressure cuff), then the result might be a shifting of the entire curve to the left or right. This would be very bad if only one or the other of the curves was shifted because one would think that the two curves were either more or less different than they really were. On the other hand if the same miscalibrated cuff were used to measure both groups, then they might be both shifted the same amount. That would be less problematic because the difference between the two groups would still be the same even if the actual pressure readings were incorrect.
As we have already discussed, we can reduce the intrinsic variability of our experimental population by controlling or eliminating factors that influence our subjects' response, but which are unrelated to the factor that we are studying. For example, white laboratory mice are preferable to wild mice as test subjects in drug trials because the white mice have experienced nearly identical environmental conditions and are genetically very similar. With reference to Fig. 7, white lab mice would have very narrow curves (small standard deviations) and the curves could be relatively close together without having a very large area of overlap.
Finally, the experimental effect is represented by the difference between the peaks of the two response curves. The experimental effect can range from zero (if the null hypothesis is correct and the treatment has no effect) to larger values (if the alternative hypothesis is correct and the treatment has an effect). If there is a non-zero experimental effect, it can sometimes be made greater by increasing the intensity of the treatment. This would result in a greater separation between the peaks in Fig. 7 and a decreased area of overlap. However, there are usually limits to the intensity of the treatment since more intense treatments may result in death or damage to the experimental subjects.
Clearly coming up with a strategy for differentiating among the different sources of variability is important for an experimental scientist. The subject of controlling experimental conditions so that unwanted variability is reduced and experimental effects are increased is called experimental design and will be a major focus of this course. The mathematical tools for measuring and assessing variation (statistics) are also very important and we will develop skills in using them over the next several weeks.
